
このページではLLM(チャットAI)をllama.cppで実行する方法を紹介します。
例えとして、gemma-4-E2B-it-Q4_1.ggufを使って環境構築を行います。
前提
以下の環境で試験を行っています。
| OS | Windows11 |
| メモリ | 32Gbyte |
環境構築
llama.cppのインストール
下記サイトから環境にあったパッケージをダウンロードします。
対応するパッケージは以下を参考にしてください。
| 環境 | パッケージ |
| NVIDIAのGPU | Windows x64 (CUDA 12) / Windows x64 (CUDA 13 ) |
| AMDのGPU | Windows x64 (Vulkan) |
| GPUなし(CPUで実行) | Windows x64 (CPU) |
CPUで実行するパッケージはx64とArm64がありますが、Snapdragonなどよっぽど変わったCPUを使った環境でないかぎりx64で問題ありません。
Releases · ggml-org/llama.cpp
LLM inference in C/C++. Contribute to ggml-org/llama.cpp development by creating an account on GitHub.
github.com
ダウンロードが完了したらzipを任意のフォルダに解凍してインストール完了です。
モデルのダウンロード
使用するモデルをダウンロードします。
gemma-4-E2B-it-Q4_1.ggufは以下のページにあります。

unsloth/gemma-4-E2B-it-GGUF at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
llama.cppの実行
以下のコマンドをパッケージを解凍したフォルダで実行します。
llama-cli.exe -m モデルパス
gemma-4-E2B-it-Q4_1.ggufを同じフォルダに置いている場合、コマンドは以下のようになります。
llama-cli.exe -m ./gemma-4-E2B-it-Q4_1.gguf
以下のように表示されたらチャットが行えます。日本語の入力も可能です。
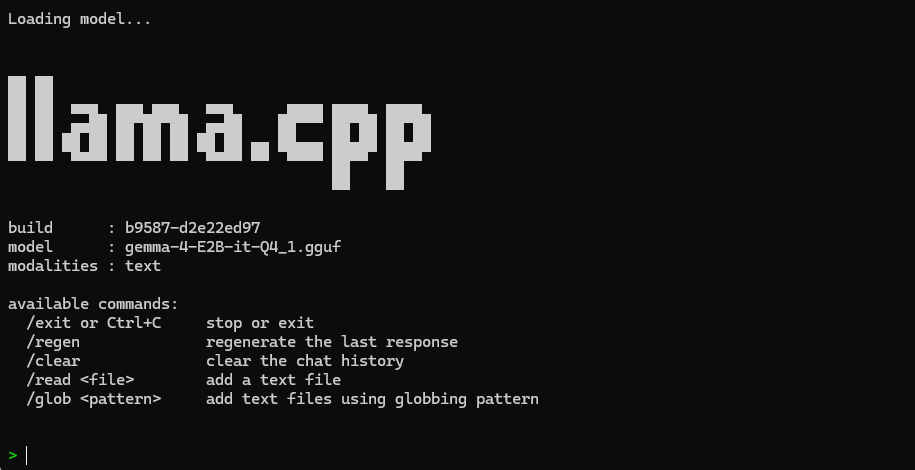
例
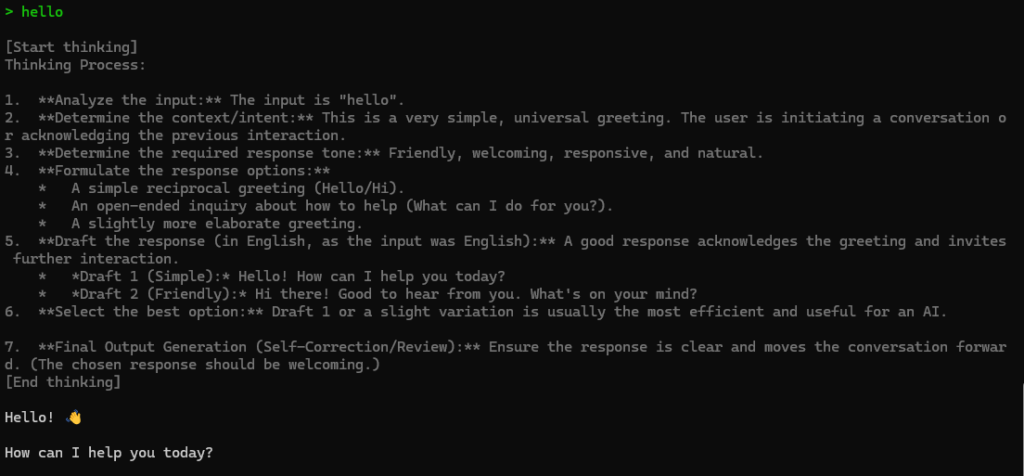
Thinking Processも表示されました
終了
Ctrl+Cでアプリケーションを終了することができます。
トラブルシューティング
モデルの中には拡張子がsafetensorsのものもありますが、使用できないようです。
拡張子がggufのものをダウンロード、使用してください。(”モデル名 gguf”で検索するとだいたいHungingfaceのページが引っかかります。)